This is a guest post by Lauren Algee, senior innovation specialist with the Library’s Digital Innovation Lab.
What yet-unwritten stories lie within the pages of Clara Barton’s diaries, the writings of civil rights pioneer Mary Church Terrell or letters written by constituents, friends and colleagues to Abraham Lincoln? With the launch of crowd.loc.gov, the Library of Congress is harnessing the power of the public to make these and many other collection items accessible to everyone.
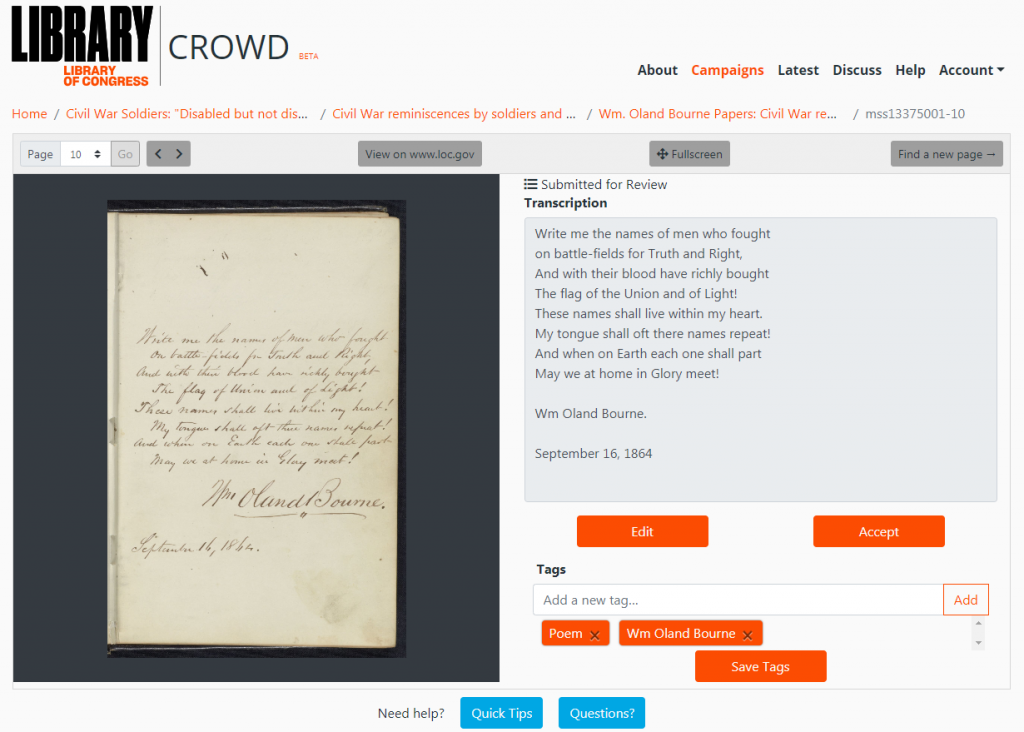
Crowd.loc.gov invites the public to volunteer to transcribe (type) and tag with keywords digitized images of text materials from the Library’s collections. Volunteers will journey through history first-hand and help the Library while gaining new skills – like learning how to analyze primary sources or read cursive.
Finalized transcripts will be made available on the Library’s website, improving access to handwritten and typed documents that computers cannot accurately translate without human intervention. The enhanced access will occur through better readability and keyword searching of documents and through greater compatibility with accessibility technologies, such as screen readers used by people with low vision.
A poem, written in 1864 by poet, editor and clergyman William Oland Bourne (1819–1901), is now transcribed and tagged in crowd.loc.gov, greatly increasing its readability and accessibility.
The pages awaiting transcription represent the diversity of the Library’s treasures. Today, volunteers can choose to work on selections from the papers of Mary Church Terrell, letters the public wrote to Abraham Lincoln, Clara Barton’s diaries, Branch Rickey’s baseball scouting reports or memoirs of disabled Civil War veterans. We’ll continuously add new materials. Coming soon are documents related to women’s suffrage, Civil War veterans, American poetry, the history of psychiatry and more.
So how does it work? We import digitized items into the platform from loc.gov. Volunteers type what they see in an image, check transcripts created by others and tag images, enhancing existing collections metadata. We expect to release the first set of publicly transcribed materials in early 2019.
Participatory projects like these are known as crowdsourcing, meaning that they invite the public – nonspecialists and specialists alike – to engage with collections and process information. This is not the Library’s first foray into these approaches.
We have long invested in building digitized collections and making them searchable. Our first attempt to recruit volunteers to increase their findability began in 2008 when the Library’s Prints and Photographs Division published thousands of photographs on Flickr Commons. For more than 10 years, this project has invited the public to help identify people and places in the photographs, generating rich information about them.
Two additional crowdsourcing efforts within the Library – the American Archive of Public Broadcasting’s Fix-It initiative and the Library of Congress Labs’ Beyond Words project – invited people to transcribe historical public broadcasting programs and to identify cartoons and photographs in the Library’s historic newspaper collections. These projects have demonstrated the passion of volunteers for history and learning as well as the knowledge and expertise the public has to share with the Library.
Crowd.loc.gov runs on an open-source software, Concordia, developed based on the user-centered design principles. It has been open source from the beginning and is available in the Library’s Github repository. Because Concordia is open source, other libraries and organizations can use the code to create transcription projects focused on their own collections.
Have we got you curious? Good! Consider visiting crowd.loc.gov today to contribute to our Letters to Lincoln Challenge. We hope to inspire volunteers to finish transcribing 10,000 items from the Abraham Lincoln Papers by the end of 2018. Help us meet our goal by transcribing at least one page and sharing your work with others.
















