This is a guest post by Flynn Shannon, who interned this summer in the Library’s Communications Office through the Junior Fellows Program. He is a student at Kenyon College, where he is pursuing a degree in classical mathematics with a concentration in scientific computing. The post was first published on “The Signal,” a blog covering the Library’s digital initiatives.
Before coming to the Library of Congress as a junior fellow, I had no concept of how large or varied its collections are. Over 167 million items are kept at the Library. Of these, more than 24 million are books. That leaves around 143 million more things. Included in this number are such effects as George Gershwin’s piano, the contents of Abraham Lincoln’s pockets the night of his assassination and more contemporary content, such as web comics.
During my time at the Library, I focused on the over 1 million images available digitally, anywhere in the world. Specifically, I was tasked with designing and developing a proof-of-concept Chrome browser extension to increase awareness of and interaction with digital images with no known copyright restrictions. These images are of particular interest because they can be used freely for any purpose.
Once installed, the extension will change the background of each new tab to a random picture from the Library’s collections that is free to use and reuse. The extension will encourage the use of these images by giving users the option to easily download, email and share the photos on Facebook and Twitter. Users will also be encouraged to learn more about the items by interacting with them on the Library’s website. By clicking on the title of any image, the user will be taken directly to the item’s page on loc.gov. Similar extensions have been created by Europeana, the New York Public Library and MappingVermont.
In developing the extension, my first step was to make a manifest.json file. This process is documented in the .zip file you can access on the free-to-use browser extension experiment page.
I was able to use a field called “chrome_url_overrides” to replace the default new tab with a custom web page built like any other using HTML, CSS and JavaScript.
Basic user interface of the Library’s free-to-use browser extension.
Once I had finished the front end, I needed pictures for the background. After reading reviews of similar extensions, I noticed that the most common complaint was that there weren’t enough unique images. Soon after installing, users began to see the same pictures over and over. Because of the size of the Library’s collections of digital images, I hoped that this wouldn’t be a problem.
The folks at LC Labs pointed me to some Jupyter Notebooks that made obtaining data from accessing bulk images on the Library’s website a breeze. I was able to create a method of getting the metadata I needed about each photo from its URL by making only slight modifications to code found in the notebooks.
My first inclination was to pull from all the photos available on the Library’s website. I quickly found some issues with this approach. I began to come across imagery containing offensive, negative stereotypes. Viewed in the proper context, these images provide an important look into a darker time in history. However, they were not appropriate for the purposes of this extension. In addition, not all of the photos online are without copyright restrictions.
As I began coming up with strategies to filter any offensive and copyrighted content, I had a meeting with the Library’s Prints and Photographs Division. Staff recommended that I use the photos on the Library’s Flickr channel, which have no known copyright restrictions and are curated.
Using a Python implementation of the Flickr API, I was able to find the URL of each image on the Library’s website. From there, I used the previously created method to write a JSON file that is read by the client-side JavaScript to change the image displayed. The current version of the extension is pulling from a set of more than 16,000 images available on the Library’s Flickr channel (although the Library currently has more than 30,000 images on Flickr and adds more nearly every week).
This is a screenshot from the Library of Congress free-to-use extension.
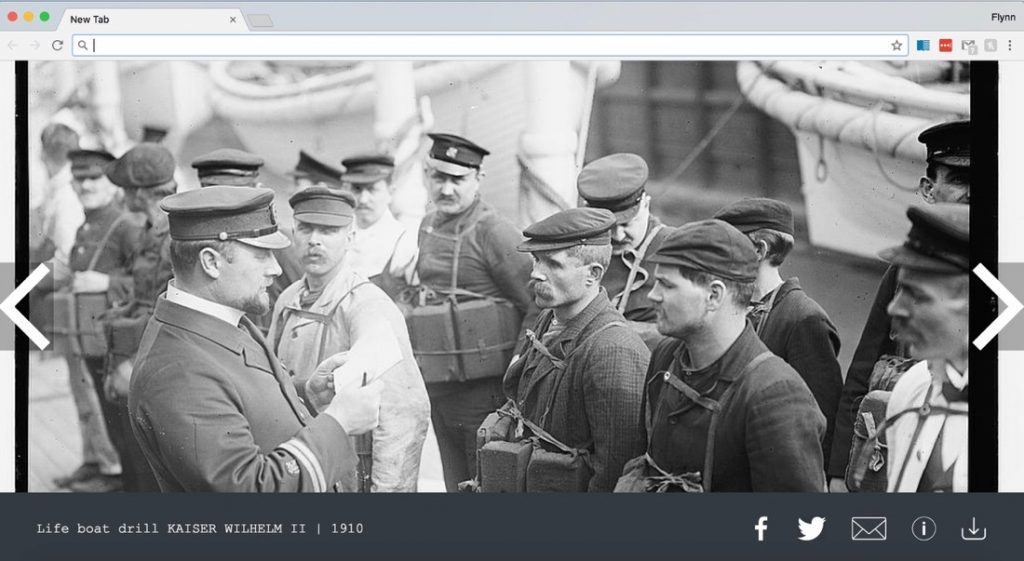
Free-to-use browser extension displaying an image from the Library with metadata and sharing options.
Try the free-to-use browser extension yourself! You’ll find instructions for download on the Library of Congress Labs Experiments Page – add a comment to this blog post to let me know what you think.














