Author: Ann Steffora Mutschler / Source: semiengineering.com
Technology begins to twist in different directions and for different markets.
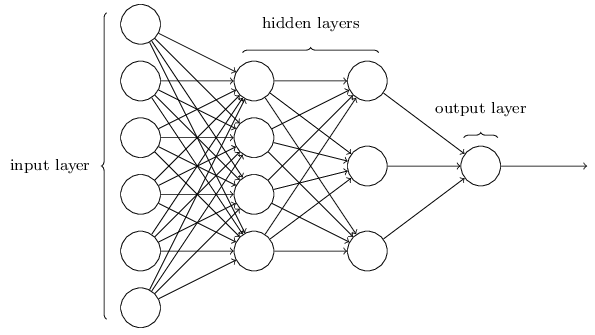
Faster chips, more affordable storage, and open libraries are giving neural network new momentum, and companies are now in the process of figuring out how to optimize it across a variety of markets.
The roots of neural networking stretch back to the late 1940s with Claude Shannon’s Information Theory, but until several years ago this technology made relatively slow progress. The rush toward autonomous vehicles — which relies on neural networking to collect data from many sensors — changed all of that. Work is underway by established companies, startups, and universities around the globe, and funding is pouring into neural networking, as well as related markets such as embedded vision, machine learning, and artificial intelligence.
“Mass market economics, increased processing power and improving computational vision techniques equals opportunities for new mass markets to be created,” said Tim Ramsdale, general manager of the Imaging and Vision Group at ARM. “But all of this has to be done in real time. Latency minimization is critical. Having lights turn on as soon as you appear at the door is critical. That means a minimum of 30 frames per second, and preferably 60 frames per second. To do that you have to have processing at the edge, and processing at the edge means low power.”
At the heart of this technology are several basic components: algorithms, very fast hardware, and optimization technology and methodologies to make these algorithms work faster using low power. The challenge is lowering the amount of computation that is required by training these systems to be more efficient.
“The key stage for neural networks is training the models, and since the training process is constantly improved, the challenge is to update trained models frequently at the target hardware and provide enough power to the algorithm execution,” said Zibi Zalewski, general manager of the hardware division at Aldec.
FPGAs can be a great solution for both problems, he said, because re-programmability allows for easy update of trained models in the hardware, while programmable logic provides the space and parallel architecture to accelerate the algorithms. “Since deep learning-based technologies appear now in commercial, industrial and safety-critical markets, the trick is to provide efficient process to update those new improvements to implementation of algorithms. This is where science meets engineering. Therefore, technologies like high-level synthesis grow to allow for a fast conversion from C++ implementation to HDL code. The challenges, of course, are to achieve the most optimal results for the hardware platform, or to pick the proper one for the algorithm.”
DSPs are starting to show up on the embedded vision side, as well. Like FPGAs, they can be programmed. But unlike FPGAs, which use floating point math, a vector DSP does computation using fixed point.
“Dynamic fixed point can take care of multiple issues,” said Tom Michiels, system architect at Synopsys. He noted that the biggest problem in running these algorithms is low power, and the best way to achieve that is by changing the order of the convolutional vectorizations. “If you organize the loops, you can maximize data use and therefore reduce the bandwidth.”
Work zone ahead
It’s not clear which processing architecture — CPU, GPU, FPGA or DSP — ultimately will be proven the winner. So far, the jury is out as to what works best and for what markets. But there is plenty of work going on behind the scenes to improve these systems.
This is about taking smarts to the next level, said Anush Mohandass, vice president of marketing and business development at NetSpeed Systems. “We are really burning the grass on getting machine learning to SoC architecture and SoC design — that’s essentially automation on steroids. Anything that’s a multi-variant problem is going to be really tough for any human or a single-dimensional machine to compute. You bring in something like machine learning or a self-learning algorithm and it’s going to perform so much better.”
Market economics support this, as well. “It’s at a place where right now if you want to do something like machine learning the concepts were there but now you don’t need to reinvent all the algorithms — you can get those algorithms from Google, you can run your servers on an AWS (Amazon Web Services) server,” he said. “What it needed in the ’80s and ’90s was a lot more investment, so the bar was really high. At that time, the hottest area for neural networks was for the stock market — neural networks predict stock markets better. But the guys who actually took it up are the guys who had the millions and billions of dollars to invest in such a technology.”
Much has changed since then. Computing technology is now…
Click here to read more














